编译原理学习笔记(一)制导翻译器
本文共 1601 字,大约阅读时间需要 5 分钟。
《编译原理》在第二章中给出了一个翻译表达式的例子(从中缀表达式到后缀表达式)。总结了如下内容:
1. 写出描述语法规则的产生式(文法包含产生式集合与符号集合) 2. 根据文法建立对应语句的语法分析树 3. 消除语言的二义性 4. 运算符的结合性以及优先级 5. 通过向文法的产生式附加属性和翻译方案得到翻译结果NC代码的文法属于上下文无关文法,构造简单(加之最近毕设要做相关内容),因此用NC程序编译器来作为学习语法制导的例子。
一条NC指令的结构如下: N.. G.. X±..Y±..Z±…..M..S..T..F..; 其中NXXX为指令编号,如N001。GXXX为G代码编号。XYZ为尺寸字,如X100代表x轴正移至100,Y-50代表y轴负向移位至50。M为M代码编号,S为主轴速度功能字,T为刀具功能字,F为进给功能字。 乍一看很麻烦,其实只是指令字的类别繁杂。NC文法产生式如下:
stmt ->N id code ; id-> num | num id num -> 0|1|2|3|4|5|6|7|8|9 code -> G X Y Z M S T F G -> ε | G id X -> ε | X char id Y -> ε | Y char id Z -> ε | Z char id M -> ε | M id S -> ε | S id T -> ε | T id F -> ε | F id char -> ε | + | -其中斜体代表非终结符,黑体代表终结符。
对于任意一句指令,可建立语法分析树。例如:
N001 G01 X100 Z-30 S300 T01 F2; 对应的语法分析树为(省略部分递推):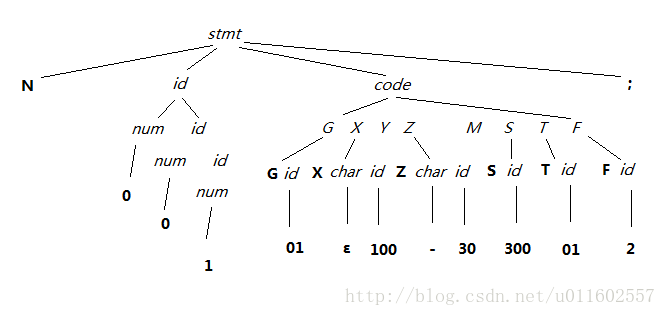
注意,这里的产生式隐含着这样一个规则:MSTF是按顺序的,即不会出现F指令在T前的情况,但实际上是有这样的代码的,在这个文法体系中,是属于错误的。
目前的内容只是对指令语句进行语法分析,并不能得到结果。要得到结果,需要向产生式附加一些规则或者程序片段,即给出对应语句的语义。
例如: 产生式: stmt ->N id code ; 语义规则: 编号为id的代码,指令为code.t。其中code.t代表code的语义。根据翻译需求,这里的语义可以是翻译为目标代码(机器语言),也可以是执行指令内容(作为解释器)。语法制导定义(syntax-directed definition)把每个文法符号和一个属性集合关联,并把每个产生式和一组语义规则相关联,这些规则用于计算与该产生式中符号相关联的属性值。
属性可以按如下方法求值:对于输入串x,首先建立其对应的语法分析树,假设一个结点N的标号为文法符号X,使用X.a表示该节点的属性a的值,并称标记了相应属性的语法树为注释分析树。对注释分析树中的每个结点上的值应用语义规则求出其属性值,从子节点求起,进行深度遍历,直到求出根结点的属性值。 [1] 这种将字符串作为属性值附在结点上的翻译方法是用来得到目标代码。另一种无需操作字符串,直接运行程序片段的方法,是用作解释器,也可得到相同的翻译结果。 语义动作(semantic action)是被嵌入到产生式体中的程序片段 简化其中的无关细节,定义语义动作: G -> ε | G id {print(“excute G %d”,id.t)} M -> ε | M id {print(excute M%d),id.t} …… 此时的语法分析树,将会多出一个额外的子结点,同样是深度遍历此树可得到翻译结果。总结:这里所用到的主要是2.1~2.3的内容,没有涉及词法语法分析,仅仅是描述一个简单的手动翻译过程:写出产生式、构造语法树、附加属性值或者程序片段、遍历树得到结果。
注:文中除了黑体标识以及引用标识属于书中内容之外,其他大部分为个人理解,仅供参考。
你可能感兴趣的文章
期货市场技术分析03_主要反转形态
查看>>
期货市场技术分析04_持续形态
查看>>
期货市场技术分析05_交易量和持仓兴趣
查看>>
TB交易开拓者入门教程
查看>>
TB创建公式应用dll失败 请检查用户权限,终极解决方案
查看>>
python绘制k线图(蜡烛图)报错 No module named 'matplotlib.finance
查看>>
talib均线大全
查看>>
期货市场技术分析06_长期图表和商品指数
查看>>
期货市场技术分析07_摆动指数和相反意见理论
查看>>
满屏的指标?删了吧,手把手教你裸 K 交易!
查看>>
不吹不黑 | 聊聊为什么要用99%精度的数据回测
查看>>
X 分钟速成 Python
查看>>
对于模拟交易所引发的思考
查看>>
高频交易的几种策略
查看>>
量化策略回测TRIXKDJ
查看>>
量化策略回测唐安奇通道
查看>>
CTA策略如何过滤部分震荡行情?
查看>>
量化策略回测DualThrust
查看>>
量化策略回测BoolC
查看>>
量化策略回测DCCV2
查看>>